クエリエディター🔗
データレイク検索クエリエディターでは、詳細検索クエリ言語のカスタム構文を使用して、お客様のテナント内の検出やイベントに対して高度で柔軟なクエリを作成できます。
クエリエディターへアクセスするには、以下の手順を実行してください。
- Taegis Menu から 詳細検索 > データレイク検索 に移動します。
- クエリエディター タブをクリックします。
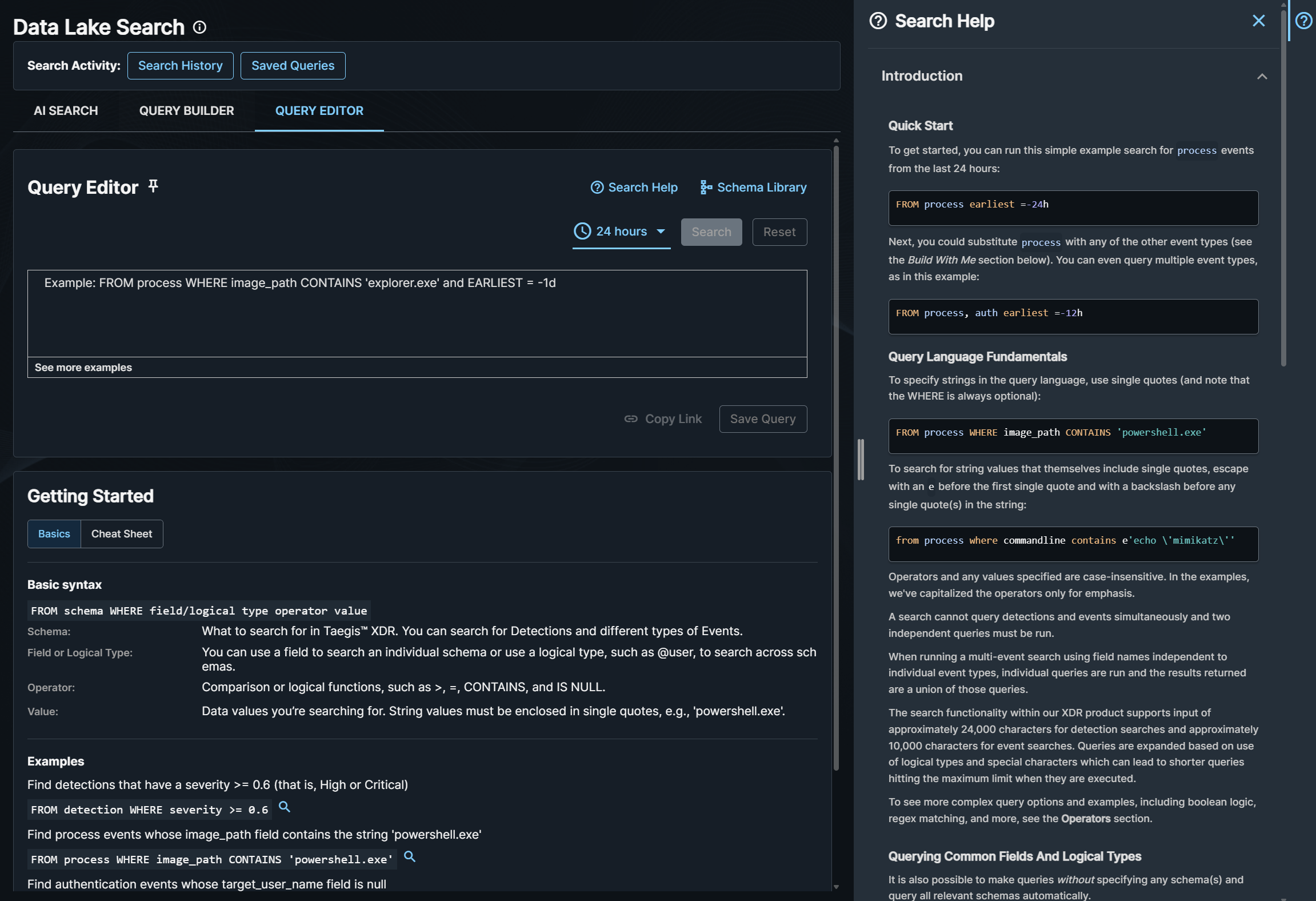
クエリの構造🔗
詳細検索クエリは、以下の構造を持ちます。
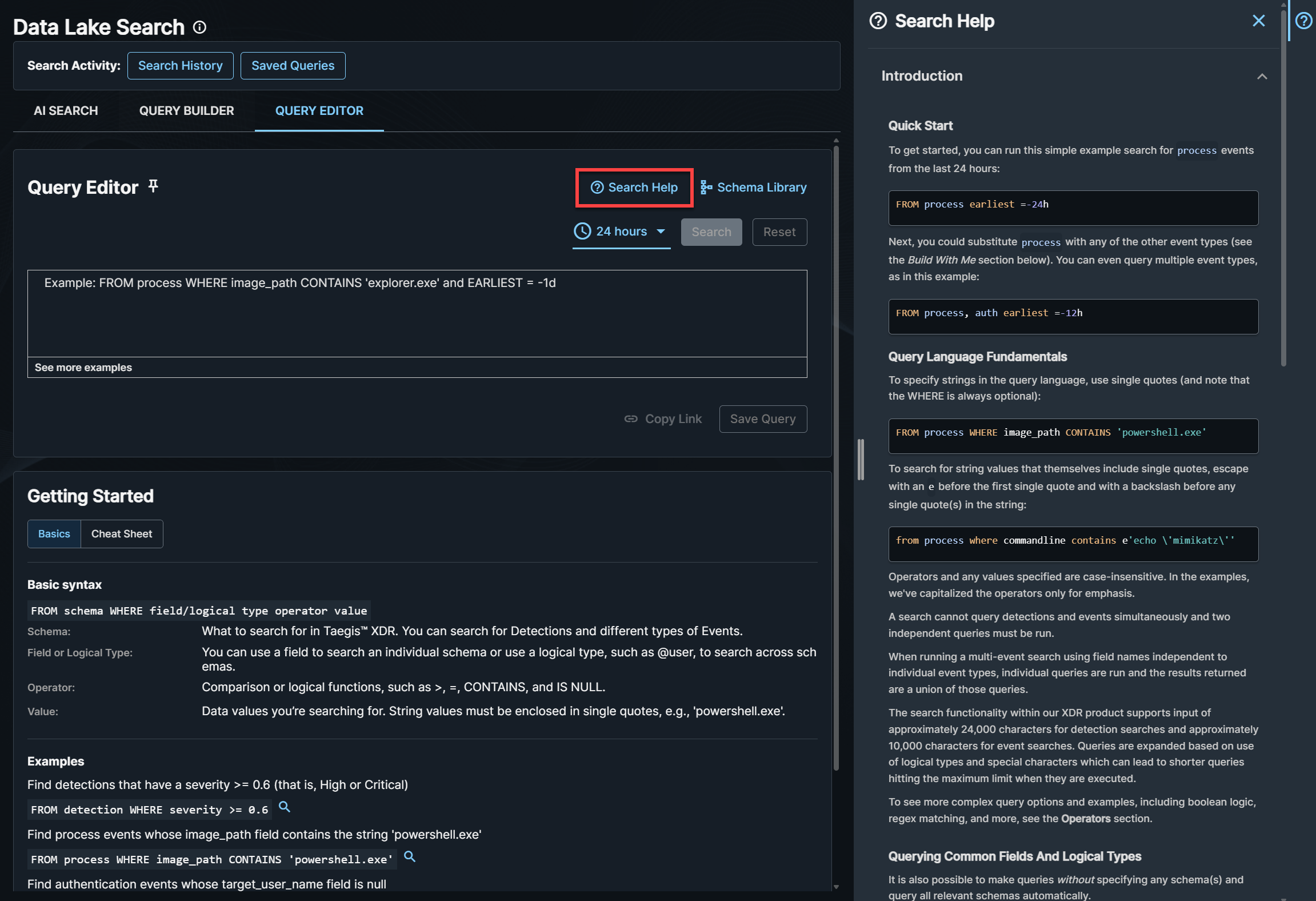
検索のヘルプ🔗
クエリエディター で、検索のヘルプアイコン をクリックすると、インラインヘルプが表示されます。内容は以下の通りです。
- 自分で作成 セクションで、成功するクエリの作成を支援
- 基本構文
- 利用可能なデータ型(スキーマ)とフィールド名(入力時にコンテキストに応じて表示)
- 演算子
- 例
ヒント
クエリ入力欄の下には、基本的なガイダンスを含む はじめに セクションもあります。
スキーマライブラリー をクリックすると、検索可能なすべてのスキーマとフィールドのリファレンスが表示されます。
コアコンセプト🔗
スキーマ🔗
- スキーマは、リレーショナルデータベースのテーブルに似たデータのカテゴリです。例として
process、auth、netflowなどがあります。検出はdetectionスキーマを使用します。詳細は スキーマ を参照してください。 -
FROMで1つまたは複数のスキーマを選択できます。ヒント
論理型 を使用する場合、
FROMを省略できます。エンジンが自動的に関連スキーマを対象とします。 -
検出とイベントを同時に検索することはできません。2つの独立したクエリを実行する必要があります。
時間ウィンドウ🔗
- ページ上部で時間範囲を調整できます。デフォルト範囲は24時間です。
- または、
earliestおよび/またはlatestを追加して時間範囲を指定できます。時間範囲 を参照してください。
フィルター(WHERE)🔗
WHEREは任意で、複数の条件をAND/ORおよび括弧()で結合できます。-
文字列はシングルクォートで囲みます。文字列内にシングルクォートを含める場合は、
e'...'形式を使用し、内部のクォートをエスケープします。以下の例を参照してください。
フィールドの解決方法🔗
- 修飾されていないフィールド名(例:
image_path)は、選択した各スキーマに存在するフィールドと照合されます。 - 複数スキーマのクエリ(例:
FROM process, auth)では、エンジンがスキーマごとにサブクエリを実行し、結果の和集合を返します。条件はそのフィールドが存在するスキーマのみに影響します。 - 明確にするために、スキーマのプレフィックスを付けてフィールドを参照することもできます(例:
process.commandline)。 -
detection.resource.idを使用して、検出を生成したイベントを検索できます。サポートされる演算子:
IS NOT NULL=CONTAINSIN
注意
Secureworks® Taegis™ XDR では、イベント検索の一貫した最適なパフォーマンスを確保するため、レート制限を実施しています。詳細は イベント検索のレート制限 を参照してください。
- 検出フィールド(例:
title)や、検出に関連するイベントフィールドでフィルタリングできます。 -
検出検索でイベントフィールドを使用する場合は、必ずイベントスキーマのプレフィックスを付けてください(例:
process.commandline)。
- 共通フィールドは複数のスキーマに存在します(例:
sensor_type)。これらを使用すると、存在するすべての場所で結果が返されます。 -
@で始まる論理型は、関連するスキーマ全体で適切なフィールドに展開されます(例:@ip、@user)。詳細は 論理型 を参照してください。
主要なルールとガードレール🔗
- 検出とイベントを同じクエリで検索することはできません。必要に応じて別々のクエリを実行してください。
- イベントフィールドを使用した検出検索では、必ずフィールドにイベントスキーマのプレフィックスを付けてください(例:
process.image_path)。 -
正規表現はバックエンドによって異なります。
- イベントはJava互換の正規表現エンジンを使用します。記法の詳細は Java正規表現ドキュメント を参照してください。
- 検出はLuceneベースの正規表現エンジンを使用します。記法の詳細は Elastic正規表現ドキュメント を参照してください。
-
Hostnameは特別なケースで、host_idに変換され、リテラル演算子(=,!=,IN,!IN)のみサポートします。ホスト名の一致は大文字・小文字を区別します。 -
@raw論理型およびoriginal_dataフィールドは、直近20日間のデータのみアクセス可能です。より長い期間の場合は、20日ごとに分割して実行するか、時間範囲を狭めてください。 - 演算子と値は大文字・小文字を区別しませんが、上記のホスト名変換は例外です。
- クエリ長の制限があります。論理型や特殊文字による展開で、見た目より短いクエリでも制限に達する場合があります。
配列🔗
配列フィールドに対するクエリはフラット化され、標準の field.subfield 記法で任意の要素に対して一致検索が可能です。
FROM http WHERE http_response_headers.record.key = 'Authorization' AND http_response_headers.record.value = 'Bearer 1234'
ヒント
上記のクエリは「'Authorization' ヘッダー」と「値が 'Bearer 1234' のヘッダー」を持つレコードを検索しますが、これらが同じヘッダーレコードであることは保証しません。特定の配列インデックスでの一致検索はサポートされていません。
演算子とブール値🔗
- 演算子は大文字・小文字を区別せず、
=,!=,>,>=,<,<=,CONTAINS,MATCHES,MATCHES_REGEX,IN,IS NULL,IS NOTなどがあります。 - 条件は
AND/OR/NOTで組み合わせます。特に複数条件の場合は、意図したロジックとなるよう括弧を使用してください。 - すべての文字列値はシングルクォートで囲み、リテラルとして解釈されます。
詳細検索クエリ言語の演算子とブール値の一覧と説明は以下の通りです。
| 演算子 | 説明 |
|---|---|
= <literal> |
大文字・小文字を区別しない完全一致。 |
!= <literal> |
等価性のブールNOT。 |
> <number> |
数値がより大きい。 |
>= <number> |
数値が以上。 |
< <number> |
数値がより小さい。 |
<= <number> |
数値が以下。 |
CONTAINS <string> |
フィールド内の文字列リテラルに対する大文字・小文字を区別しない部分一致。 |
<fieldname> !CONTAINS <string exclusion> |
フィールド内の文字列リテラルに対する大文字・小文字を区別しない部分一致の否定。 |
MATCHES <string> |
フィールド内のグロブ形式文字列パターンに対する大文字・小文字を区別するワイルドカード一致。 |
<fieldname> !MATCHES <string exclusion> |
フィールド内のグロブ形式文字列パターンに対する大文字・小文字を区別しないワイルドカード一致の否定。 |
MATCHES_REGEX <string> |
フィールド内の文字列パターンに対する大文字・小文字を区別しない正規表現一致。 |
!MATCHES_REGEX <string> |
文字列パターンに対する大文字・小文字を区別しない正規表現一致の否定。 |
IN <value list> |
フィールド値が値リストに含まれていれば真となるブール式。 |
!IN <value list> |
フィールド値が値リストに含まれていなければ真となるブール式。 |
IS NOT NULL |
フィールドが存在し、nullでないことをテスト。 |
IS NULL |
指定フィールドが存在しない、またはnullの場合に真を返す。 |
予約語🔗
以下の識別子は予約語であり、大文字・小文字を区別せず、検索語としてリテラル値で使用する場合はシングルクォートで囲む必要があります。
AGG, AGGREGATE, AND, AS, ASC, AVG, BY, CONTAINS, COUNT, CARDINALITY, DESC, DESCENDANT, EARLIEST, FALSE, FIELDS, FROM, HEAD, IN, IS, INDEX, LATEST, MATCHES, MATCHES_REGEX, MAX, MIN, NOT, NOW, NULL, OF, OR, SEARCH, SORT, SUM, TAIL, TOP, TRUE, WHERE
CIDR表記🔗
詳細検索クエリ言語は、IPアドレスフィールドに対して =(リテラル)、MATCHES、IN 演算子を使用する場合にCIDR表記をサポートします。また、これらの否定形(!=、!MATCHES、!IN)でもCIDR表記が利用できます。
現時点では、CIDR表記はイベントクエリのみサポートされます。検出クエリではCIDR表記はサポートされず、有効なIPアドレスを使用する必要があります。
例
ソースアドレスがIP範囲 192.168.2.0/24 内にあるnetflowイベントを検索:
FROM netflow WHERE source_address = '192.168.2.0/24'
IPアドレスがIPv6 CIDR範囲内にあるnetflowイベントを検索:
FROM netflow WHERE @ip IN ('2001:db8::/32')
注意
以下の MATCHES クエリは、CIDRクエリではなくテキストワイルドカード一致として動作します。
FROM netflow WHERE @ip MATCHES '192.168.2*'
以下の MATCHES クエリは、CIDRクエリとして動作します。
FROM netflow WHERE @ip MATCHES '192.168.2.*.*'
IPv6の比較はCIDRを使わない限り文字列リテラル比較です
=, CONTAINS, MATCHES をIPv6アドレスで使用する場合、値は文字列リテラルとして比較されます。圧縮・展開表記など等価なIPv6表現でも、完全に同じ書式でなければ一致しません。
書式に依存せず一致させるには、IPv6 CIDR表記を使用してください。単一アドレスの場合は /128 を使用します。
IPv6アドレスの注意点
IPv6アドレスは複数の等価な表現が可能です。例えば、以下はすべて同じアドレスを表します。
2001:db8:abcd:1234:0:1:0:0
2001:db8:abcd:1234:0:1::
2001:db8:abcd:1234:0000:0001:0000:0000
=, CONTAINS, MATCHES 演算子で検索する場合、IPv6アドレスは文字列リテラルとして比較されます。クエリで使用した書式と完全一致する場合のみ一致します。
書式に依存せずIPv6アドレスを確実に一致させるには、CIDR表記を使用してください。CIDR表記は比較前にIPv6アドレスを正規化するため、すべての等価な表現が一致します。
単一アドレスに一致させるには /128 プレフィックス長を使用します。
FROM email WHERE @ip IN ('2001:db8:abcd:1234:0:1::/128')
このクエリは、アドレスが 2001:db8:abcd:1234:0:1:0:0、2001:db8:abcd:1234:0:1::、または完全展開の 2001:db8:abcd:1234:0000:0001:0000:0000 で保存されていても一致します。
時間範囲🔗
相対または絶対の時間境界を使用して結果を制限できます。
構文:
earliest=[+-]<delta><unit>[@unit]latest=[+-]<delta><unit>[@unit]- 単位:
s(秒)、m(分)、h(時)、d(日)、w(週)、mo(月)、y(年) @unitはその単位の境界で切り捨てます。
動作:
latest のみ指定した場合、earliest は直前の24時間がデフォルトとなります。
例
注意
日付は ISO 8601標準 で指定してください。例:(2019-07-01, 2019-06-01T00:00:00)
関数🔗
検索結果は、追加の関数にパイプしてさらに絞り込むことができます。
search | functions
クエリが複数のデータ型にまたがる場合、関数は各データ型ごとに独立して動作します。
| 関数 | 説明 |
|---|---|
sort |
指定したフィールドと順序で結果をソートします。
|
head |
検索順で各イベントタイプの最初の N 件を返します。 |
tail |
各イベントタイプの最後の N 件を返します。tail は結果を逆順にしてから最後の N 件を返します。 |
tolower |
BY 句のグループ化で文字列フィールドを小文字に正規化し、大文字・小文字を区別しない集計や一貫したグループ化を可能にします。 |
toupper |
BY 句のグループ化で文字列フィールドを大文字に正規化し、大文字・小文字を区別しない集計や一貫したグループ化を可能にします。 |
fields |
API専用。結果に含める/除外するフィールドを選択(カラム選択のように動作)。デフォルトでは original_data 以外のすべてのフィールドが返されます。必要なフィールドのみ選択することでパフォーマンスが向上します。 |
注意
fields 関数はAPI経由のみ利用可能で、Secureworks® Taegis™ XDR UIでは利用できません。
関数を使ったクエリ例を展開して表示
-
データ型ごとに結果を制限:
-
単一イベントタイプ内でソート:
-
複数イベントタイプ内でソート(時間フィールドのみ):
-
時間の切り捨てを伴うソート:
-
ユーザー名・ドメイン・ホスト名でグループ化し、小文字正規化したauthイベントの件数:
-
ドメインでグループ化し、大文字正規化したauthイベントの件数:
-
フィールドの選択(APIのみ):
集計🔗
aggregate を使用すると、クエリ結果をグループ化し、指定した操作を実行できます。
集計クエリは以下の形式を取ることができます。
| 演算子 | 説明 |
|---|---|
sum |
クエリで返されたすべての行のフィールドの合計を計算します。 |
min |
フィールドの最小値を取得します。 |
max |
フィールドの最大値を取得します。 |
avg |
クエリで返されたすべての行のフィールドの平均値を取得します。 |
count |
フィールドを持つ行数をカウントします。フィールドを指定しない場合はすべての行をカウントします。 |
cardinality |
フィールドの一意かつnullでない値を持つ行数をカウントします。 |
(aggregate) by |
指定したフィールドの値ごとに結果をグループ化または集計し、各値の件数を表示します。 |
by
by 句は、オプションでフィールドリストまたは時間単位を指定でき、指定したフィールドや時間単位ごとに結果をグループ化します。
単位は以下の通りです。
s— 秒m— 分h— 時d— 日
集計を使ったクエリ例を展開して表示
-
過去24時間のPowerShell関連プロセスイベントをユーザー名ごとにグループ化して件数をカウント:
-
ユーザー
bobの過去3日間の最初と最後の認証イベント時刻を返す: -
過去1日のDNSクエリエベントを1時間ごとに集計して件数をカウント:
注意
集計はイベントクエリのみサポートされます。複数イベントクエリの場合、集計はイベントタイプごとに実行されます。論理型での集計はサポートされていません。
よく使われるクエリパターン🔗
よく使われるクエリ例を展開して表示
-
フィールド指定による単一スキーマ検索:
-
共通フィールドによる複数スキーマ検索:
-
FROMなし(論理型によるスキーマ非依存検索) -
検出フィールドによる検出検索:
-
関連イベントフィールドによる検出検索:
-
スキーマ内での論理型検索: